From “Tech on the Cheap” to “Tech Because I’m Obsessed”
Forget about cheap; I’m nuts and I spend way too much money on my home lab.
Five months ago, I planned a “Tech on the Cheap” series covering open-source and inexpensive solutions. I wrote one post, blasted it on LinkedIn, then… crickets. I’m officially abandoning that whole idea.
Truth is, I spend money on stuff I don’t need to satisfy my personal curiosity. While I started with budget-friendly options like Raspberry Pi, I’ve since invested thousands in hardware. To some, that’s “a bunch of money”, but to others, “pocket change”, making a “cheap tech” series both constraining and subjective.
Instead, I’m shifting focus to my constantly evolving home lab — present and future. This post catches you up on how we got here.
Home Lab Evolution
Why Build Personal Infrastructure?
I’m a builder and I like spinning up services on a whim without accumulating technical debt from manual setups. I’m obsessive about resilience and operational excellence — automation, monitoring, redundancy, fault tolerance, self-healing. Most importantly, what I build needs to be self-managing. If it isn’t, then each new thing will require maintenance, which will take away a little bit of my time to build new things. Ultimately, I become imprisoned by the maintenance burden of my creations and I either shut things down or stop building new things.
Development Growing Pains
My first services ran on modest hardware with GitHub repos full of bash scripts, GoCD configs, and docker compose files. Fine for simple stateless services, but my HA Mattermost cluster showed the limits — labor-intensive deployment pipelines with tightly coupled components.
The Quest for Better Infrastructure
I needed more hardware without managing a bunch of snowflakes. Kubernetes alone wouldn’t cut it since I needed to run VMs too. This sent me down the on-premises cloud rabbit hole.
OpenStack? Learning curve too steep, hardware requirements too specific. After months of failure (though I learned Ansible), I moved on.
Apache CloudStack seemed promising. My proof-of-concept worked, so I went all-in, buying matching Dell R630 servers for high availability. I gutted my 42U rack and rebuilt everything… only for things to fail spectacularly when scaling up.
The Solution Was There All Along
I completely ignored Proxmox VE initially. ‘Too basic,’ I thought — just KVM and LXC containers.
I’m an idiot.
I could have saved a year of my life. Proxmox VE does exactly what I need with minimal fuss. HA groups, replication, backups, SDN, converged storage, firewalls, metrics, multi-tenancy, cloud-init, etc. There’s a lot there, and I use almost all of it. I even have a few LXC containers. Ha!
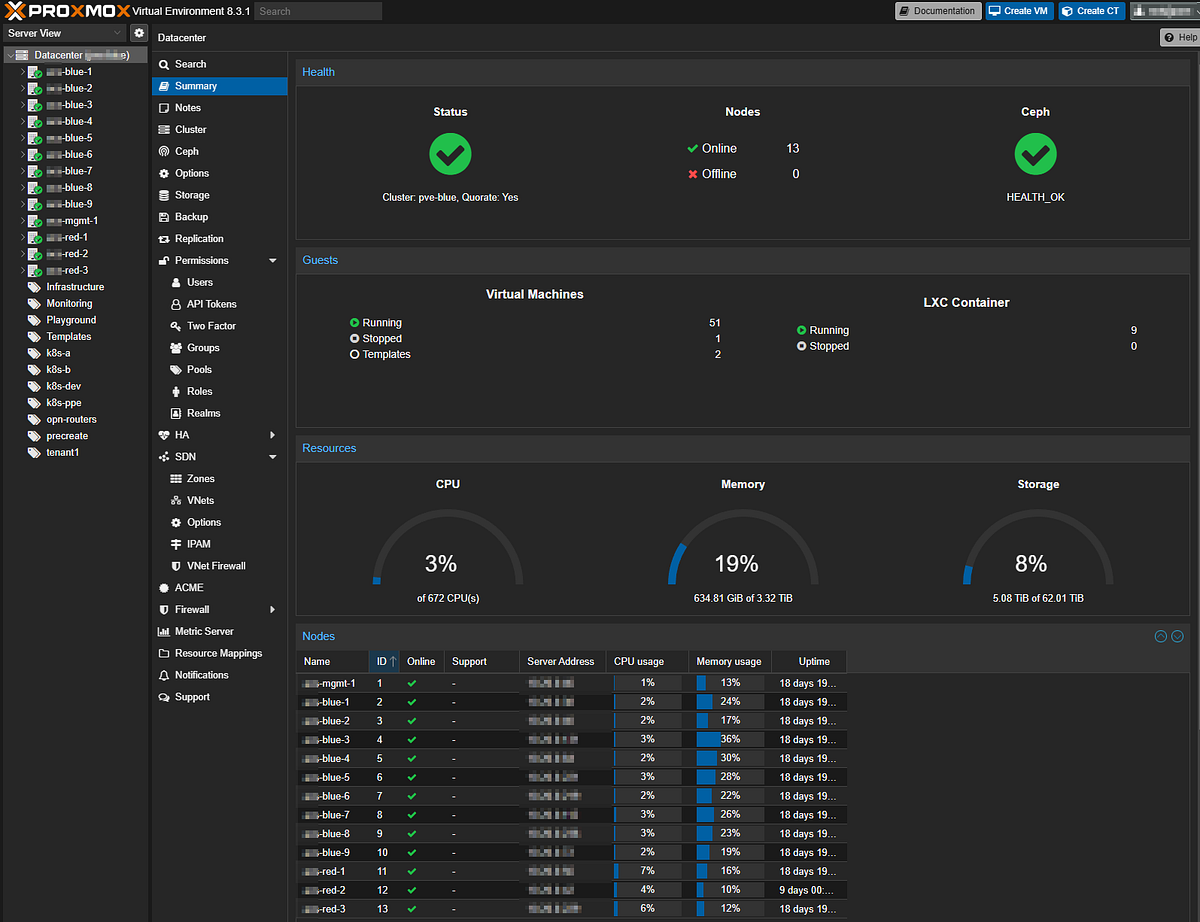
With Proxmox VE handling all of my hypervisor needs, my next challenge is container orchestration.
Kubernetes Clusters
Earlier, I mentioned my HA Mattermost cluster and the labor-intensive deployment pipeline. My cluster runs on 4 VMs and I use docker compose along with GoCD and bash scripts. The problem is orchestrating containers to maintain high availability — I’ve got nothing. Kubernetes has a Mattermost orchestrator and, well, container orchestration is sort of its thing.
Prior to building an on-premises Kubernetes cluster, my experience was with AWS EKS. I always found it frustrating how long it took to spin up a new cluster. I have a much better appreciation for what goes on behind the scenes and difficulty involved.
I’m using CephFS and Ceph Rados Block Devices (RBD) for storage in my PVE cluster. This works fine for everything but the control plane nodes running etcd. Etcd requires low-latency block devices for stability. My Ceph RBD storage introduced too much network latency, causing constant control plane failures. According to best practices, etcd needs SSD or NVMe disks — preferably single-level cell (SLC) SSDs for write-intensive workloads.
Now I need to buy SLC SSDs and/or NVMe disks…tech on the cheap… yeah… right.
Closing Thoughts
What’s Next
The “tech on the cheap” series isn’t a bad idea but it’s disconnected from what I’m really into at the moment. This week I’m upgrading my network infrastructure — replacing two of my L2 Aggregation switches with a pair of L3/L2 switches to boost my core bandwidth from 10Gbps to 100Gbps and eliminate my Unifi Gateway Pro as a single-point-of-failure.
Check back next week to see where I’m at.